Ever tried to picture a day without Google? Imagine navigating through your day without the luxury of instant answers, the ability to discover new places, or satisfy your endless curiosity at the click of a button. It sounds almost impossible, right? This seamless interaction with information is powered by the incredible advancements in Natural Language Processing (NLP). From smart assistants like Amazon Alexa, Google Assistant, and Apple’s Siri to chatbots like ChatGPT and Gemini, NLP is the driving force behind the effortless searches and smart responses we rely on daily. But what exactly is NLP, and how does it transform our digital experiences? Let’s dive in and explore the history behind these powerful tools that have become integral to our lives.
What is NLP?
Natural language processing (NLP) is an interdisciplinary sub field of computer science and information retrieval. It is primarily concerned with giving computers the ability to support and manipulate human language. It involves processing natural language datasets, such as text corpora or speech corpora, using either rule-based or probabilistic (i.e. statistical and, most recently, neural network-based) machine learning approaches.(Wikipedia)
This simplifies it : Natural Language Processing (NLP) is a field of computer science that enables computers to understand, interpret, and respond to human language.
Who would have thought that in present day and age we would be communicating with computers in text , speech or video formats, this advancement wasn’t a sudden leap or discovery that was recently made in the present time but the earliest initiatives of NLP were made during the 17th century, when philosophers such as Leibniz and Descartes put forward proposals for codes which would relate words between languages. All of these proposals remained theoretical, and none resulted in the development of an actual system until the 1950s.
The development of NLP in different time frames can be distinguish by the the different approaches mentioned below:
- Heuristic Based Methods
- Machine Learning Based Methods
- Deep Learning Based Methods
1. Heuristics-Based Methods
In the realm of Natural Language Processing (NLP), heuristic methods are a way to tackle tasks by using rules of thumb or general guidelines. These aren’t rigid sets of instructions, but rather flexible strategies that help make decisions about the text. These methods were predominant in the early stages of NLP.
1950s-1960s: Early Rule-Based Systems
- 1950s: Turing Test proposed by Alan Turing, a conceptual test for machine intelligence.
- 1964-1966: ELIZA by Joseph Weizenbaum, one of the earliest natural language processing programs that used pattern matching and substitution methodology to simulate conversation with a human.
1970s-1980s: Rule-Based Parsing and Grammar
-
- 1970: SHRDLU by Terry Winograd, a program that could understand and respond to commands in natural language within a restricted “blocks world” environment.
- 1980s: LFG (Lexical Functional Grammar) and HPSG (Head-Driven Phrase Structure Grammar), frameworks for syntactic structure in languages, influencing computational parsing methods.
2. Machine Learning-Based Methods
Only rules, and instruction sets could not meet the demand and requirements of the ever growing industry, the advancements in the domain of Machine Learning which was pioneered by Arthur Lee Samuel who popularized the term “machine learning” in 1959.The Samuel Checkers-playing Program was among the world’s first successful self-learning programs, and as such a very early demonstration of the fundamental concept of artificial intelligence (AI)
Machine Learning (ML) methods leverage statistical models and algorithms to learn patterns from data. These approaches gained prominence as computational power and data availability increased.
1990s: Introduction of Statistical Models
- 1990s: Transition from purely rule-based methods to statistical approaches.
- 1994: Hidden Markov Models (HMMs) for part-of-speech tagging, introduced by Eric Brill.
- 1997: Maximum Entropy Models for natural language processing tasks, such as text classification and sequence labeling.
Early 2000s: SVMs and Conditional Models
-
- 2000: Support Vector Machines (SVMs) applied to text categorization (Thorsten Joachims).
- 2001: Conditional Random Fields (CRFs) by John Lafferty, Andrew McCallum, and Fernando Pereira, which became popular for sequence labeling tasks like named entity recognition (NER).
3. Deep Learning-Based Methods
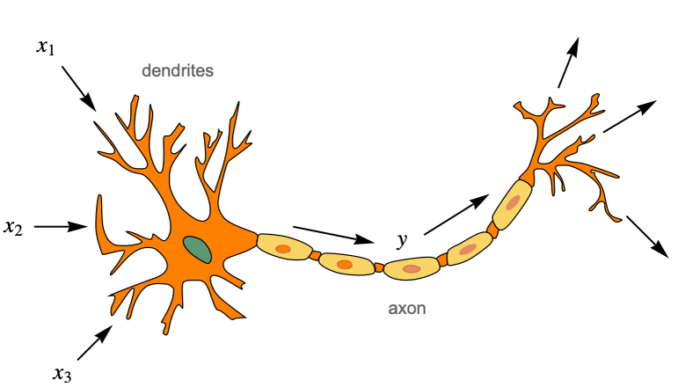
The first computational model of a neuron was proposed by Warren MuCulloch (neuroscientist) and Walter Pitts (logician) in 1943 following the multiple AI winters(An AI winter is a period of decreased funding and interest in artificial intelligence research.), as the advancements such as Multi Layer Perceptron , Back Propagation Algorithms, Recurrent Neural Networks and so on, Deep Learning (DL) methods utilized neural networks with multiple layers to automatically learn features and representations from data. Although these methods require more data than Machine Learning methods, this approach has revolutionized NLP in recent years.
2010s: The Rise of Neural Networks
- 2013: Word2Vec by Tomas Mikolov et al., introducing efficient methods for word embeddings, transforming word representation in NLP.
- 2014: Sequence-to-Sequence (Seq2Seq) Models by Ilya Sutskever, Oriol Vinyals, and Quoc V. Le, applying LSTMs to machine translation.
- 2014: GloVe (Global Vectors for Word Representation) by Jeffrey Pennington, Richard Socher, and Christopher Manning.
2015: Attention Mechanism and Transformers
-
- 2015: Attention Mechanism introduced by Bahdanau, Cho, and Bengio in the context of neural machine translation, significantly improving performance.
- 2017: Transformers by Vaswani et al., in the paper “Attention is All You Need”, eliminating the need for recurrent networks and enabling parallel processing.
2018-2020: Pre-trained Language Models
-
-
- 2018: BERT (Bidirectional Encoder Representations from Transformers) by Jacob Devlin et al., achieving state-of-the-art results on a wide range of NLP tasks.
- 2019: GPT-2 (Generative Pre-trained Transformer 2) by OpenAI, demonstrating the ability to generate coherent and contextually relevant text.
- 2020: T5 (Text-to-Text Transfer Transformer) by Colin Raffel et al., proposing a unified framework that converts all NLP tasks into a text-to-text format.
-
2021-Present: Advancements in Language Models
-
-
-
- 2021: GPT-3 by OpenAI, with 175 billion parameters, showcasing significant advancements in text generation and understanding capabilities.
- 2022: BERT Variants and Improvements, such as RoBERTa (Robustly optimized BERT approach) and DistilBERT (a smaller, faster, cheaper version of BERT).
- 2023: ChatGPT based on GPT-4, further improving conversational AI capabilities
-
-
New methods in NLP have not developed in isolation but have built upon the concepts and processes of previous approaches. These methods have collectively shaped the current landscape of natural language processing.